

Technical Seo
~~# Technical SEO
~~# Technical SEO
What is Technical SEO
Technical SEO is about improving your website to make it easier for search engines to find, understand, and store your content.
It also involves user experience factors. Such as making your website faster and easier to use on mobile devices.
Done right, technical SEO can boost your visibility in search results.
Benefits of Technical SEO
- Improves Search Engine Ranking: Technical SEO helps websites rank higher in search engine results by addressing structural issues that may hinder indexing and ranking.
- Increases Page Speed: Optimizing website speed enhances user experience and is a key ranking factor.
- Ensures Crawlability and Indexability: Proper technical SEO ensures search engines can easily crawl and index a website, improving visibility.
- Eliminates Duplicate Content: Addressing duplicate content issues can prevent search engine penalties and improve rankings.
- Enhances User Experience: Faster loading times, secure connections (HTTPS), and mobile optimization improve overall user satisfaction.
- Enables Rich Snippets: Implementing structured data can lead to rich snippets in search results, increasing click-through rates.
- Wider Reach and Engagement: Improved site structure and performance can lead to higher engagement and broader audience reach.
Important Aspects of Technical SEO
XML Sitemap
An XML sitemap is a file that tells search engines like Google which URLs on your website should be indexed (added to its database of possible search results).
It may also provide additional information about each URL, including:
- When the page was last modified
- How often the page is updated
- The relative importance of the page
This information can help search engines crawl (explore) your site more effectively and efficiently. And better match your pages with relevant search queries.
- Why is it important
An XML sitemap is highly recommended if you want your pages to show in search engine results.
If you don’t provide an XML sitemap, search engines have to rely on hyperlinks (on your site or elsewhere) to discover pages on your site. This is inefficient and it can lead to pages being missed.
- How can we Generate it?
It’s likely that the platform you use to manage your website’s content automatically generates and updates your XML sitemap.
You may be able to find yours by going to **yourdomain.com/**sitemap.xml in your browser.
Like this:
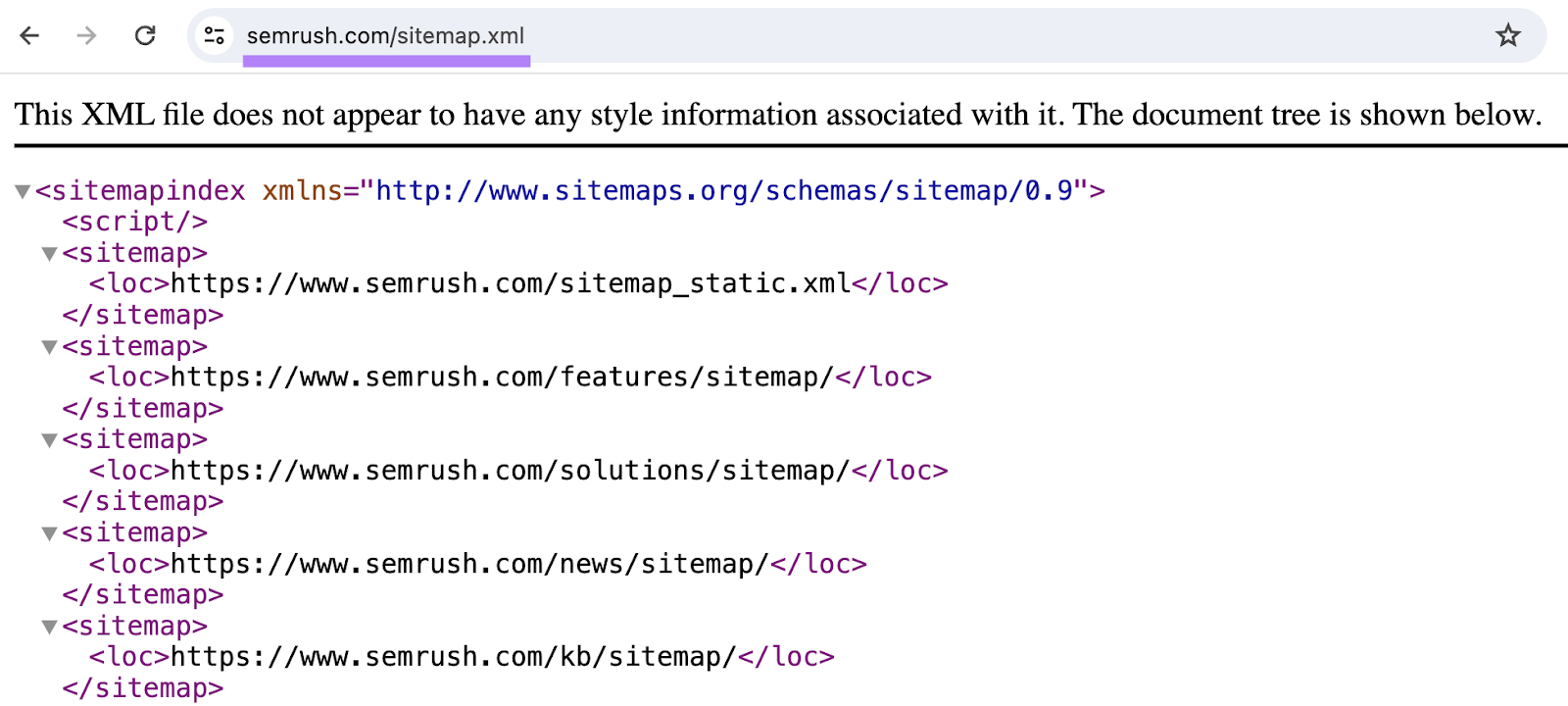
(This should work if you’re using WordPress, Wix, Squarespace, or Shopify.)
Otherwise, refer to the help center for your website builder or content management system (CMS). Or contact your platform’s support team.
If your platform doesn’t provide an XML sitemap, you can use a sitemap generator tool.
If you use a tool outside of your platform to create a sitemap, make sure to publish it to your site to make it live.
Instructions For Developers Related to Sitemap
- Identify Key Pages to Include
- Homepage: Ensure the main page is included.
- Product Pages: Include all individual product pages.
- Category Pages: Add all category and subcategory pages.
- Static Pages: Include important static pages such as About Us, Contact Us, Terms & Conditions, and Privacy Policy [Read More].
- Use Sitemap Generation Tools
- Use online sitemap generators like XML Sitemaps or plugins for your CMS (e.g., Yoast for WordPress) to automatically create and update the sitema [Refer].
- Optimize the Sitemap Structure
- Hierarchical Organization: Maintain a clear hierarchy reflecting the site's structure.
- Avoid Deep Nesting: Keep the sitemap simple and avoid deep nesting to ensure easy crawling.
- Include Essential Metadata Tags
- Last Modified (
<lastmod>): Indicate the last modification date of each page. - Change Frequency (
<changefreq>): Specify how frequently the content changes (e.g., daily, weekly). - Priority (
<priority>): Assign priority values to pages based on their importance [Read More].
- Regular Updates and Maintenance
- Regularly update the sitemap to reflect changes in the site's content.
- For dynamic sites, ensure the sitemap is updated frequently and submit it to search engines each time there is a significant change [Read More].
- Submit the Sitemap to Search Engines
- Submit the sitemap to Google Search Console and Bing Webmaster Tools to help search engines discover and index the pages efficiently.
- Monitor and Troubleshoot
- Use tools like Google Search Console to monitor the sitemap and resolve any issues.
- Ensure that the sitemap is being crawled and indexed correctly [Read More].
Lets Understand it with a Example
Company URL - https://www.travisperkins.co.uk/sitemap.xml
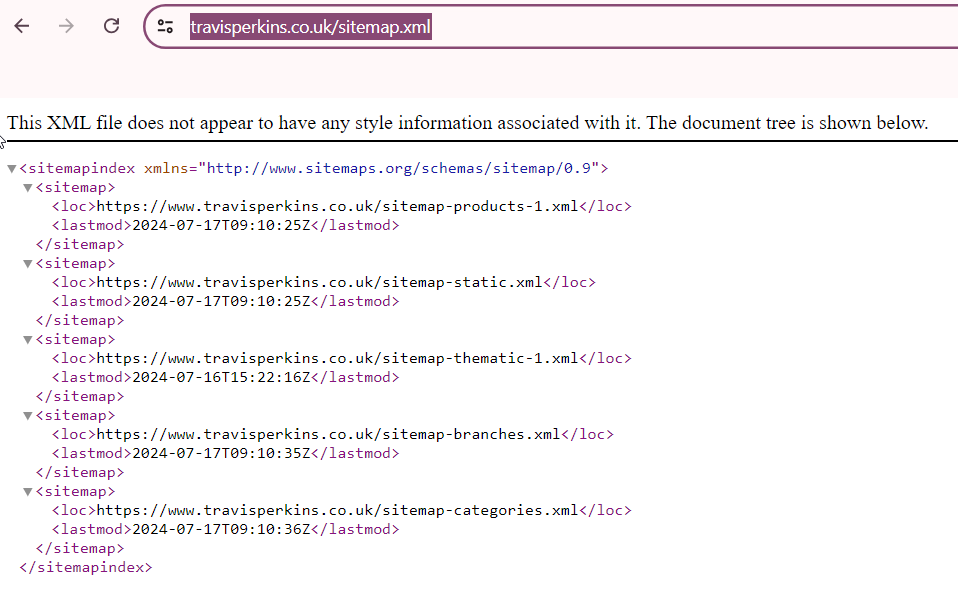
Sitemap Index Structure
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">- This is the root element of the sitemap index, declaring the XML namespace used for sitemaps.
Individual Sitemaps
Each <sitemap> element contains two child elements: <loc> and <lastmod>.
<sitemap>
<loc>https://www.travisperkins.co.uk/sitemap-products-1.xml</loc>- This specifies the URL of the sitemap file that lists product pages.<lastmod>2024-07-17T09:10:25Z</lastmod>- This indicates the last modification date and time of the product sitemap file.
<sitemap>
<loc>https://www.travisperkins.co.uk/sitemap-static.xml</loc>- This specifies the URL of the sitemap file that lists static pages such as About Us, Contact, etc.<lastmod>2024-07-17T09:10:25Z</lastmod>- This indicates the last modification date and time of the static sitemap file.
<sitemap>
<loc>https://www.travisperkins.co.uk/sitemap-thematic-1.xml</loc>- This specifies the URL of the sitemap file that lists thematic content pages.<lastmod>2024-07-16T15:22:16Z</lastmod>- This indicates the last modification date and time of the thematic sitemap file.
<sitemap>
<loc>https://www.travisperkins.co.uk/sitemap-branches.xml</loc>- This specifies the URL of the sitemap file that lists branch locations.<lastmod>2024-07-17T09:10:35Z</lastmod>- This indicates the last modification date and time of the branches sitemap file.
<sitemap>
<loc>https://www.travisperkins.co.uk/sitemap-categories.xml</loc>- This specifies the URL of the sitemap file that lists product categories.<lastmod>2024-07-17T09:10:36Z</lastmod>- This indicates the last modification date and time of the categories sitemap file.
To know More Visit: https://www.sitemaps.org/protocol.html
How to Submit Your XML Sitemap to Google
To Submit your sitemap, sign into Google Search Console.
And go to “Indexing” > “Sitemaps.”
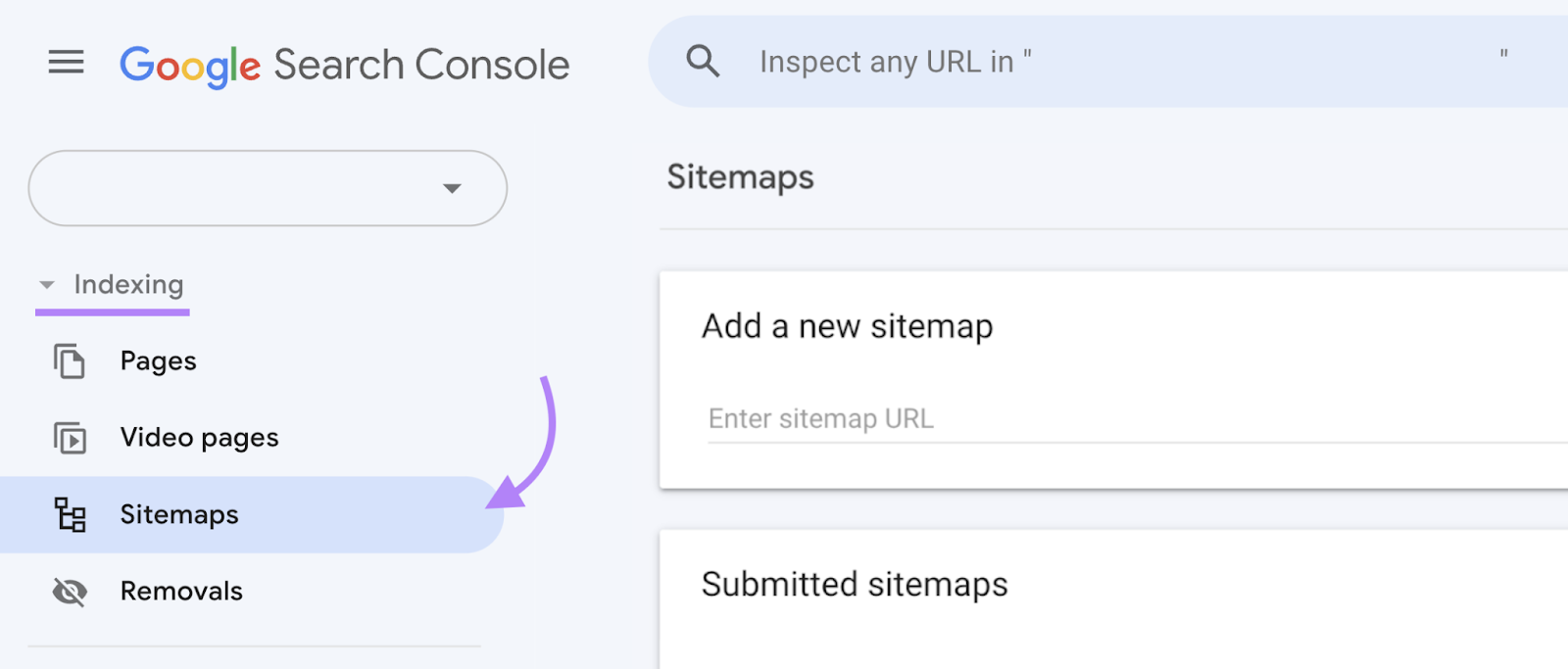
Enter your sitemap’s URL into the “Add a new sitemap” section.
And click “Submit” when you’re done.
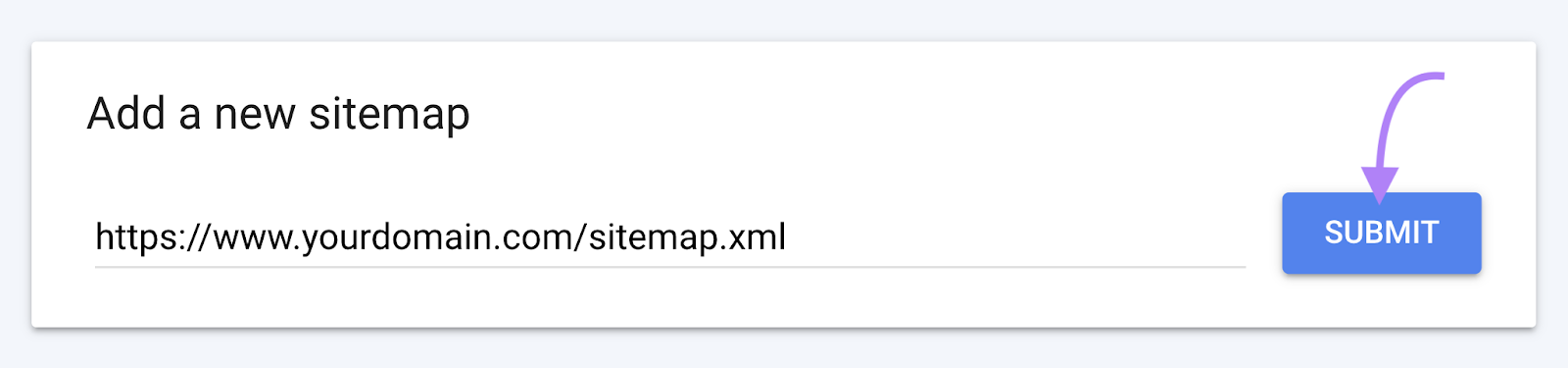
You should then see your file in the “Submitted sitemaps” section.
When Google has crawled your sitemap, you’ll see a “Success” notice in the “Status” column.
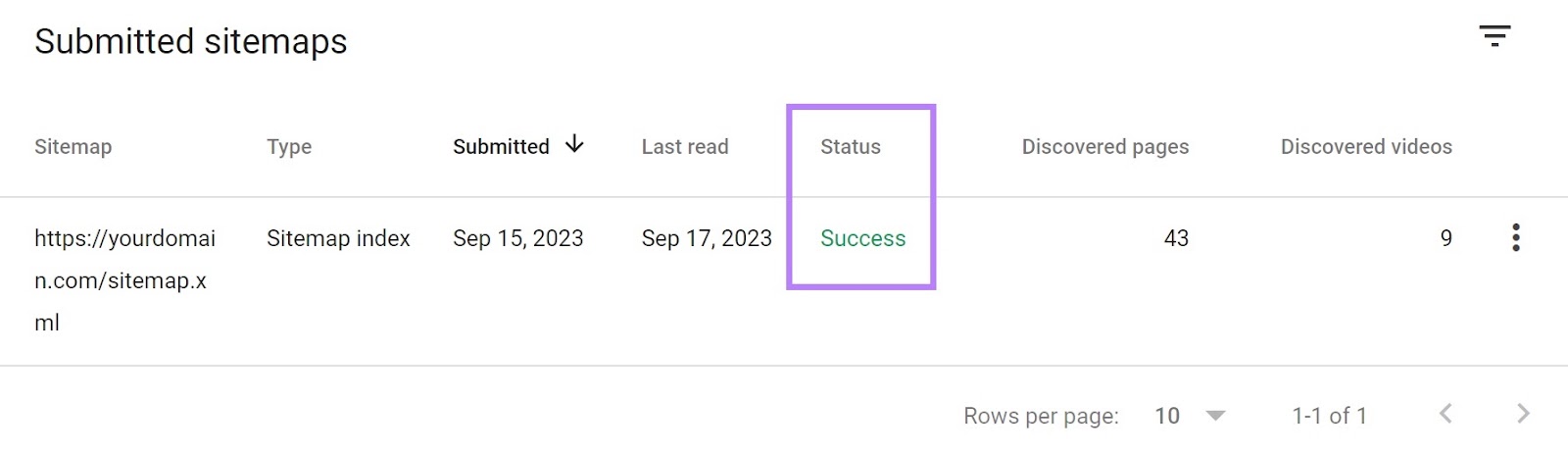
Google will periodically re-crawl your SEO sitemap to check for any changes.
But if you make major changes that you want to be discovered quickly, you can re-submit your sitemap with a new request.
To know more about XML sitemap read semrush blog
Other Types of Sitemap
But before I go further, you must know that there is one more type of sitemap format:
- HTML SiteMap:
This is more like your content sitemap that users can see and use to navigate your site. They're also commonly referred to as your "website archive."
While HTML sitemaps might help users find pages on your site, as , your internal linking should take care of that anyways. So the focus from an SEO perspective should be on XML sitemaps.
There are four main types of sitemaps:
- Normal XML Sitemap: This by far the most common type of sitemap. It’s usually in the form of an XML Sitemap that links to different pages on your website.
- Video Sitemap: Used specifically to help Google understand video content on your page.
- News Sitemap: Helps Google find content on sites that are approved for Google News.
- Image Sitemap: Helps Google find all of the images hosted on your site.
Read: The 8 Best Sitemap Generator Tools
Why are Sitemaps Important?
Search engines like Google, Yahoo and Bing use sitemap to find different pages on your site.

“If your site’s pages are properly linked, our web crawlers can usually discover most of your site.”
In other words: you probably don’t NEED a sitemap. But it definitely won’t hurt your SEO efforts. So it makes sense to use them.
There are also a few special cases where a sitemap really comes in handy.
For example, Google largely finds webpages through links. And if your site is brand new and only has a handful external backlinks, then a sitemap is HUGE for helping Google find pages on your site.
Or maybe you run an ecommerce site with 5 million pages. Unless you internal link PERFECTLY and have a ton of external links, Google’s going to have a tough time finding all of those pages. That’s where sitemaps come in.
Search engines like Google, Yahoo and Bing use your sitemap to find different pages on your site.
“If your site’s pages are properly linked, our web crawlers can usually discover most of your site.”
In other words: you probably don’t NEED a sitemap. But it definitely won’t hurt your SEO efforts. So it makes sense to use them.
There are also a few special cases where a sitemap really comes in handy.
For example, Google largely finds webpages through links. And if your site is brand new and only has a handful external backlinks, then a sitemap is HUGE for helping Google find pages on your site.
Or maybe you run an ecommerce site with 5 million pages. Unless you internal link PERFECTLY and have a ton of external links, Google’s going to have a tough time finding all of those pages. That’s where sitemaps come in.
With that, here’s how to setup a sitemap…and optimize it for SEO.
Website Architecture
Website Architecture is how a website’s pages are structured and linked together. An ideal Website Architecture helps users and search engine crawlers easily find what they’re looking for on a website.
- Why Is Website Architecture Important for SEO?
Reason #1: An optimized site architecture helps search engine spiders find and index all of the pages on your website.
If you have pages on your site that are several clicks from your homepage (or not linked from any other page at all), Googlebot will have a hard time finding and indexing those pages.

But if your site architecture is interlinked, spiders can follow your internal links to 100% of your site’s pages:

Reason #2: Site architecture sends link authority around your website.
When you internal link to high-priority pages, the more link authority (PageRank) will flow to those pages. Which can help improve their rankings in Google.

Reason #3: The right website architecture makes it easy for visitors to find what they need on your site.
(Which can indirectly help with your SEO)
Hreflang Tag
Hreflang is an HTML attribute used to specify the language and geographical targeting of a webpage. If you have multiple versions of the same page in different languages, you can use the hreflang tag to tell search engines like Google about these variations. This helps them to serve the correct version to their users.
For example, if we Google “apple official website” in the US, this is the first result:

If we do the same in Spain, we see this version of the page:

Hreflang makes this possible.
- Why does hreflang matter for SEO?
If you’ve spent time translating your content into multiple languages, then you’ll want search engines to show the most appropriate version to their users.
Catering to the native tongue of search engine users also improves their experience. That often results in fewer people clicking away from your page and back to the search results (i.e., higher dwell time), a lower bounce rate, a higher time on page, etc.—all that other good stuff that we believe has a positive impact on SEO and rankings.
Both Google and Yandex look at hreflang tags to help do this.
- What does a Hreflang tag look like?
Hreflang tags use simple and consistent syntax:
<link rel="alternate" hreflang="_x_" href="https://example.com/alternate-page" />
Here’s what each part of that code means in plain English:
- link rel=“alternate”: The link in this tag is an alternate version of this page.
- hreflang=“x”: It’s alternate because it’s in a different language, and that language is x.
- href=“https://example.com/alternate-page”: The alternate page can be found at this URL.
404 Error Pages
A 404 page, or error page, is the content a user sees when they try to reach a non-existent page on our website. It 's the page your server displays when it can 't find the URL requested by the user.
How to Find 404 Errors
- Run a Site Audit: Use tools like Screaming Frog or other site audit tools to scan your website for any pages returning a 404 error. These tools will provide a detailed report of all broken links.
- Check Google Search Console: Navigate to Google Search Console and look under "Settings -> Crawling Stats -> By Response" to see which pages are returning a 404 status code according to Google's index.
- Filter by Response Codes: In your site audit tool, click on the Response Codes tab and filter for Client Error 4XX to identify 404 errors specifically. This will help you pinpoint exactly which URLs are affected.
- Review Broken Link Reports: Utilize broken link crawl tools to generate reports that highlight all links leading to 404 errors. These tools are particularly useful for ongoing maintenance and quickly identifying new issues.
How to Fix 404 Errors
- Fix or Restore the Page: If the content previously existed and was removed by mistake, restore the original page from backups or recreate the content. This resolves the error by bringing the requested page back online.
- Redirect the URL: Use 301 redirects to send users to a relevant page if the original content is no longer available or relevant. This ensures users are guided to useful content instead of hitting a dead end.
- Update Internal Links: Check and update any internal links pointing to the 404 pages. Ensure all hyperlinks on your site are accurate to prevent users from encountering 404 errors.
Page Speed
Page speed (also called “load speed”) measures how fast the content of a page loads. From an SEO standpoint, having a fast page speed is essential.
Many factors, such as your web hosting and your page size, affect page load speed. Page speed also differs on the desktop and mobile versions of a page.
Why Is Page Speed Important for SEO?
Page load speed is a confirmed ranking factor on desktop and mobile.
In other words:
Faster loading times (along with other important signals) can contribute to higher rankings.
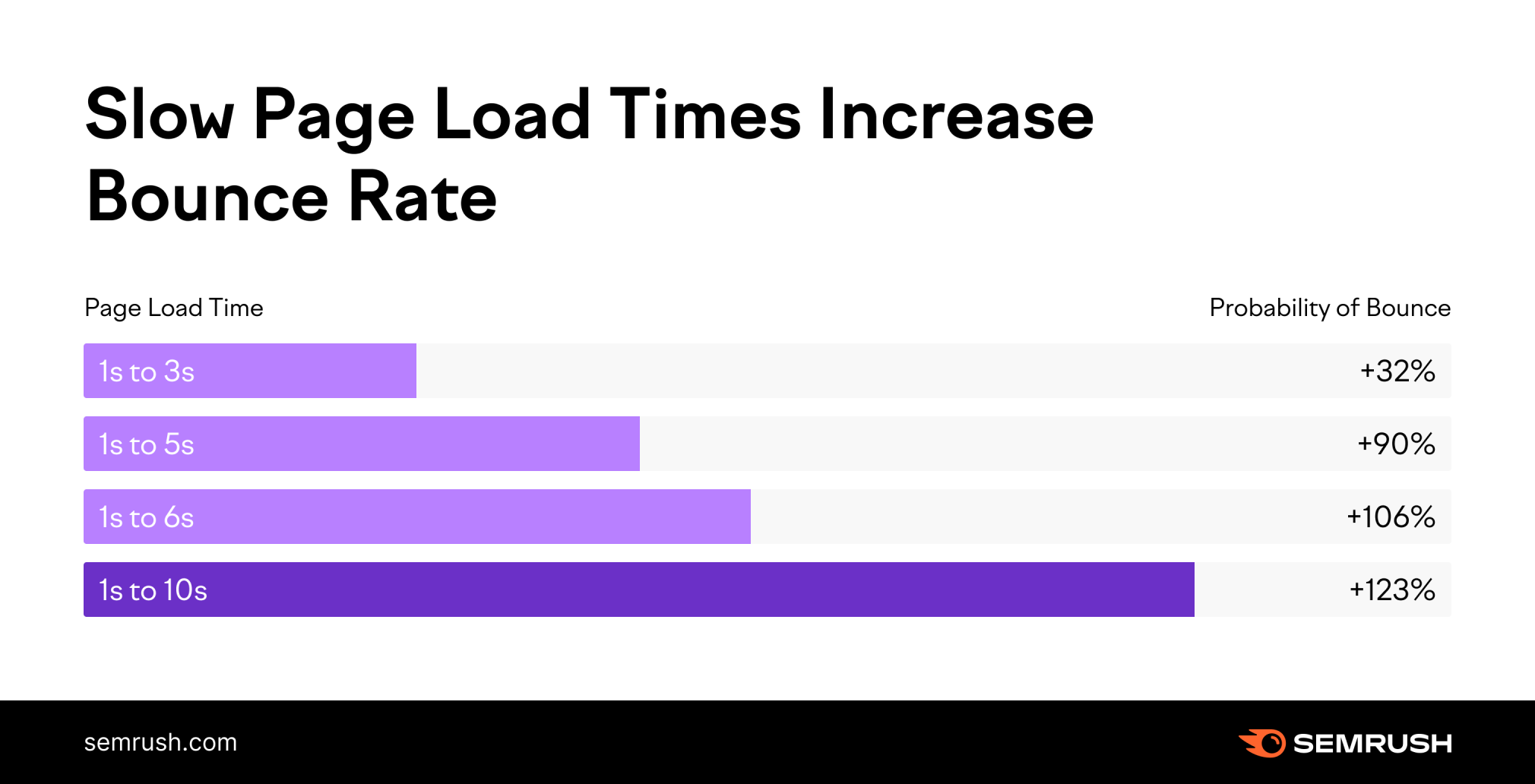
Page speed affects your search engine rankings because slow sites negatively affect user experience.
In fact, the probability of bounce almost triples if your page takes longer than three seconds to load, according to Google.
But it’s important to clarify:
“Page speed” is not a single metric. It acts as an umbrella term.
Why?
Because there are many ways to measure page speed. (Check out some tools that do so below.)
Say a user types a domain into their web browser and presses “enter.”
After a short time, the site opens.
Sometimes, the first thing the user sees is a blank page.
A few milliseconds (or seconds) later, users see some elements. Maybe a block of text or an image.
At a certain point, the user can interact with the page. They can click a button, for example.
While users wait, the content on the page might move around as new elements load.
And, eventually, the content of the page fully loads.

Sometimes, by the time the page loads completely, users have already found what they were looking for.
Other times, they have given up and left the page.
As you can see, a lot happens when you’re loading a site. And everything happens at a different pace.
You can measure each of these events separately. That’s why we say page speed is not a single metric, but many.
Common page speed metrics include the following:
- Time to First Byte (TTFB): How long it takes for the page to begin loading
- First Contentful Paint (FCP): How long it takes for the user to see the first element of a page (like an image)
- Onload time: How long it takes to fully load the content of a page
Next, we’ll provide guidance on what a good page speed is based on Google’s Core Web Vitals.
How Core Web Vitals Affect Page Speed
Google’s Core Web Vitals are a set of metrics that score the user experience of a page. Google uses these three metrics to get a picture of loading speed based on actual speed, webpage interactivity, and visual stability:
- Largest Contentful Paint (LCP) measures how long it takes for your main content to load. It should be 2.5 seconds or less.
- First Input Delay (FID) measures how long it takes until a user can interact with a page. It should be of 100 milliseconds or less.
- Cumulative Layout Shift (CLS) measures how often users experience layout shifts. Your CLS score should be 0.1 or less.
You need to understand Core Web Vitals to optimize page speed.
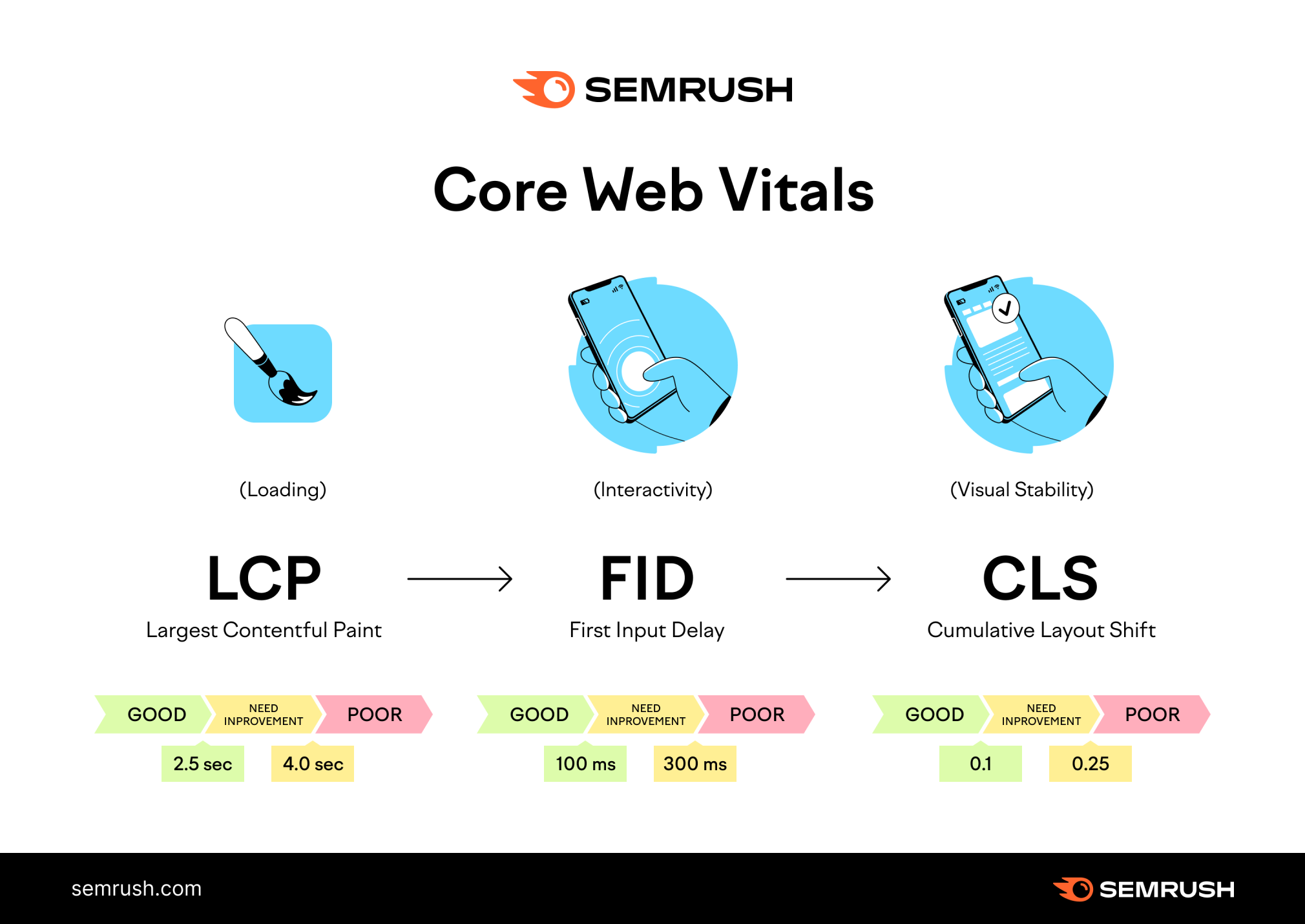
You can use these metrics to gauge how fast your page should be. Google classifies your site’s Core Web Vitals as “Good,” “Needs Improvement,” or “Poor.”
You can check your scores in the Core Web Vitals report in Google Search Console.
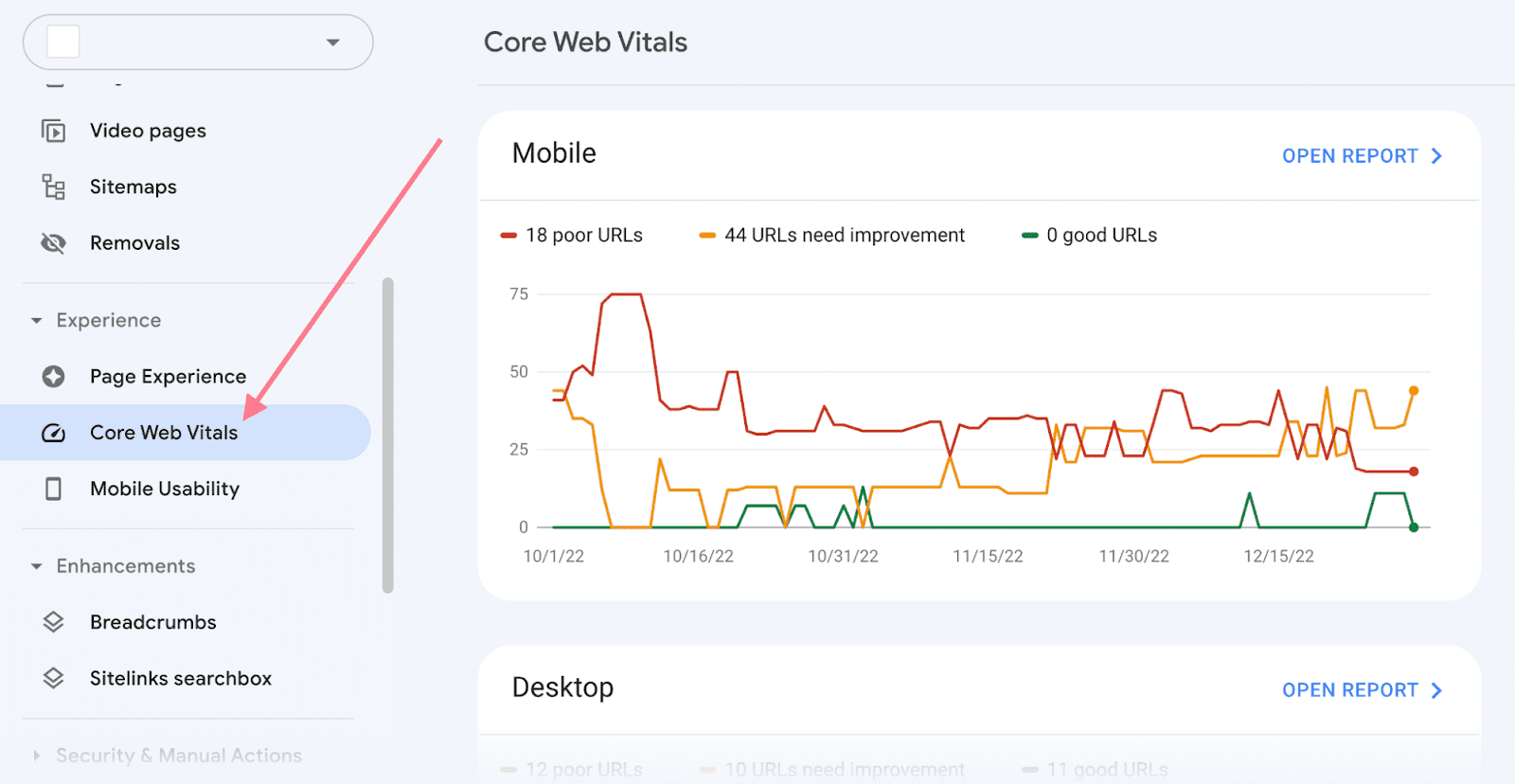
Note: Google says its page speed updates only negatively affect pages that deliver “the slowest experience.” But they recommend aiming for the "Good" threshold for best results. Once you hit that threshold, you won't necessarily see huge gains by micro-optimizing your page speed by a few milliseconds.
To summarize:
Optimizing pages with poor performance should be your priority. Because Google can penalize your site if you don’t.
And above all:
Don’t put page speed before good content. Because relevance will always come first.
A page that loads a “tiny bit faster” won’t necessarily outrank other slower pages. Because relevance and search intent are more important.
So you should first prioritize creating content that meets users’ needs.
With that said, these are Google’s thresholds to evaluate the Core Web Vitals of a page:
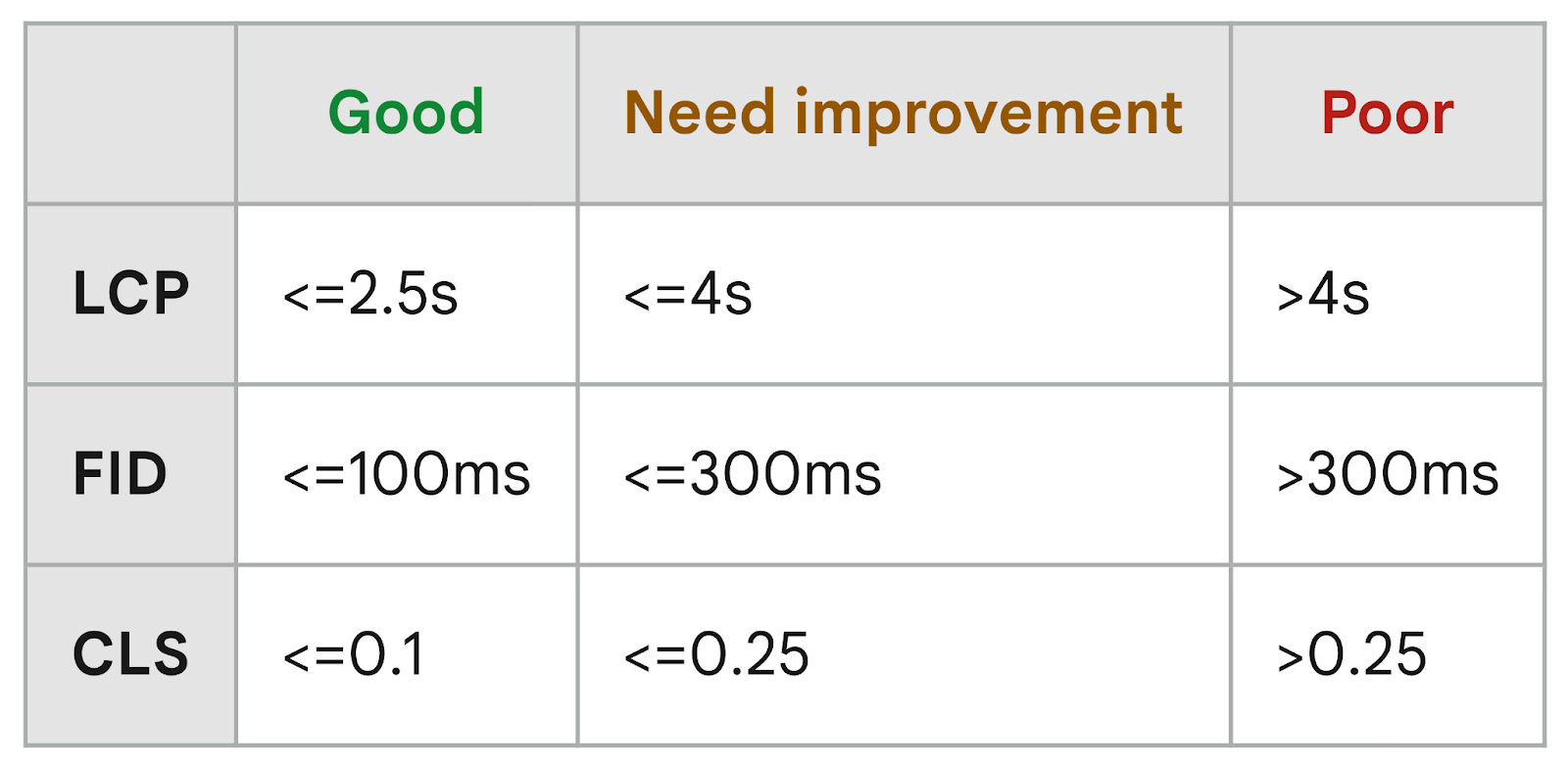
The Core Web Vitals are part of a bigger set of quality signals called Web Vitals. This list constantly evolves and includes other relevant metrics like TTFB and FCP.
To learn more, read our guide to Core Web Vitals and how to improve them.
Link Source - https://backlinko.com/technical-seo-guide
Robot.txt File
A robots.txt file is a set of instructions telling search engines which pages should and shouldn’t be crawled on a website. Which guides crawler access but shouldn’t be used to keep pages out of Google's index.
A robots.txt file looks like this:
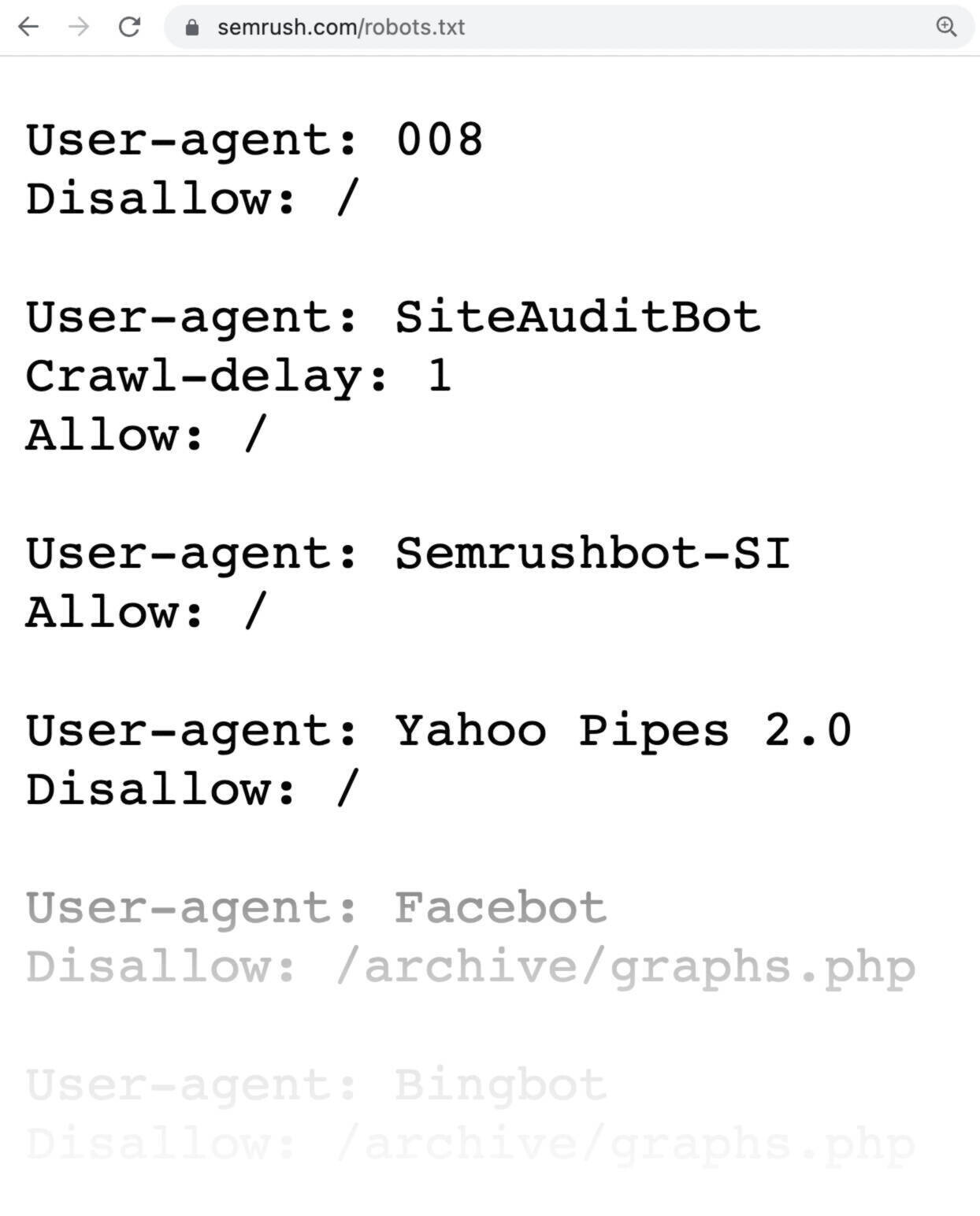
Robots.txt files might seem complicated, but the syntax (computer language) is straightforward.
Before we get into those details, let’s offer some clarification on how robots.txt differs from some terms that sound similar.
How to Set up a Robots.txt File
- Create the File: Open a plain text editor like Notepad (Windows) or TextEdit (Mac) and create a new document named robots.txt.
- Add Rules: Define the rules for web crawlers. Use "User-agent" to specify the crawler and "Disallow" to block access to specific parts of your site. For example:
- javascript
- Copy code
- User-agent: *
- Disallow: /private/
- Upload to Root Directory: Save and upload the robots.txt file to the root directory of your website. This is typically where your homepage is located.
- Verify and Test: Use tools like Google Search Console to verify that the robots.txt file is correctly configured and accessible to web crawlers.
To know more visit liquidweb create a robots txt file blog
HTTP and HTTPs
What is HTTP?
Every link you click that starts with HTTP uses a basic protocol known as Hypertext Transfer Protocol (HTTP or “protocol”). HTTP is a network protocol standard that defines how messages are formatted and transmitted and what actions web servers and browsers should take in response to various commands.
Whenever you enter a URL into your web browser, your computer sends a request to the server that hosts the website you’re trying to visit. That server sends back a response, usually the website’s HTML code. This communication between your computer and the server happens over port 80 for unsecured connections (i.e., without using SSL protocol).
What is HTTPS?
HTTPS is an extension of the Hypertext Transfer Protocol (or simply put, “protocol”). The S in HTTPS stands for “secure.” When a website is encrypted with TLS (or SSL), it uses Hypertext Transfer Protocol Secure (HTTPS).
Basically, it’s HTTP with encryption. It is used to secure communication over a computer network and is widely used on the Internet. HTTPS encrypts and decrypts user page requests and the pages returned by the web server.
This protects against man-in-the-middle attacks and the confidentiality of data sent between the browser and the website. HTTPS connections use port 443 by default.
Differences Between HTTP vs HTTPS
The most significant difference between the two protocols is that HTTPS is encrypted and secured using digital certificates, while HTML is not. When you visit a website using HTTPS, your connection to that site is encrypted. Any information you send or receive on that site is also encrypted.
Another difference between the protocols is that HTTPS uses port 443, while HTML uses port 80. Port 443 is the standard port for secured Hypertext Transfer Protocol (HTTPS). Port 80 is the default port for unsecured Hypertext Transfer Protocol (or “protocol”).
What is Crawling
Crawling is the discovery process in which search engines send out a team of robots (known as crawlers or spiders) to find new and updated content. Content can vary — it could be a webpage, an image, a video, a PDF, etc. — but regardless of the format, content is discovered by links.
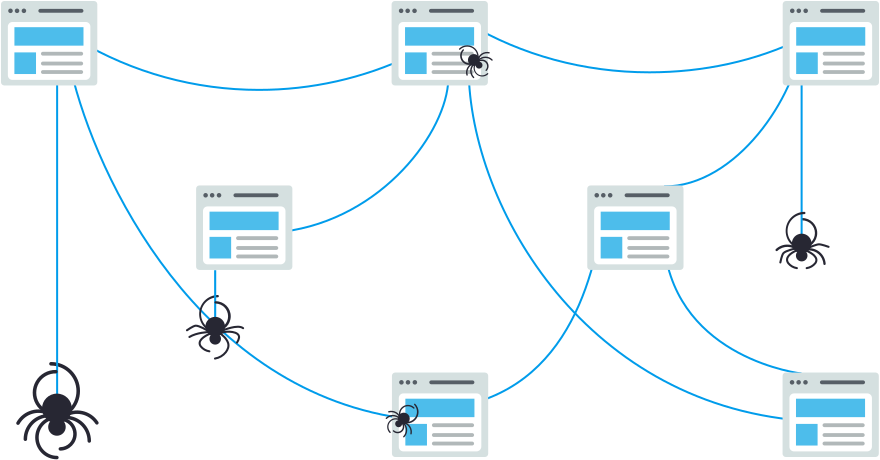
Googlebot starts out by fetching a few web pages, and then follows the links on those webpages to find new URLs. By hopping along this path of links, the crawler is able to find new content and add it to their index called Caffeine — a massive database of discovered URLs — to later be retrieved when a searcher is seeking information that the content on that URL is a good match for.
This is the factor why we do internal linking with pages that have good traffic and high amount of refering domains.
What is Indexing?
Indexing is defined as the process of storing and organizing web pages that search engine bots have crawled. After a crawler accesses a page, the data collected is then added to a search engine index. The index is a massive database containing information about the content and characteristics of millions of web pages.
Indexing is a vital step in search engines’ displaying quality information to users. It allows search engines to display relevant web pages in response to search queries. Search engines will use individual page indexing to look at the site’s meta tags, descriptions, and content. As they find specific keywords on the page, it increases the chances for the page to rank for the related keyword.
What is the Difference Between Crawling and Indexing in SEO?
“Crawling” refers to the process by which search engine bots systematically browse website pages. “Indexing” refers to search engines storing and organizing pages that have already been crawled.
Crawling precedes indexing, as search engine bots must crawl web pages to gather information before it can be indexed and made available for search engine results. The two processes are deeply interconnected as search engines sift through the database of all the content on the web.
Within the SEO community, crawling and indexing are often used interchangeably. For example, a client may ask, “Has the site been crawled yet?” or “Does this page need to be indexed?” This isn’t a problem, as crawling and indexing in SEO are tied together. However, as an SEO expert or web developer, it’s essential to understand the differentiation between the two concepts.
How To Check if Your Site is Being Crawled and Indexed
Ensuring your website pages are being crawled and indexed is fundamental for your site pages to rank on Google. To check, you can use a few different tested methods. You can either test manually through Google Search or use Google Search Console. In this next section, we’ll go over how to check and the benefits of both.
Method #1: Manual Check (Input “Site:” Before URL)
The easiest and fastest way to check if a web page is being crawled and indexed is to perform a manual check. Follow these steps:
- Visit the page that you would like to check.
- Within the URL search bar, double-click to highlight the entirety of the URL.
- Before the http or https, input “Site:” and hit enter.
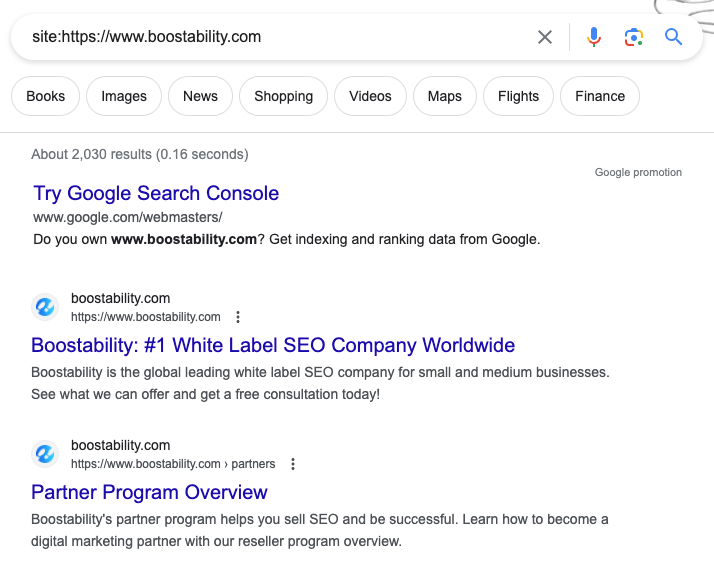
Once you click enter, you should see the Google search page with either no, one, or multiple results. If there aren’t any results, the page has not been crawled or indexed by Google. If there are results, double-check to ensure the specific page you want to check is listed.
- Once you find the page, click the three dots next to the URL and above the link (title tag).
- Clicking the three dots indicates when the page was first crawled and indexed.
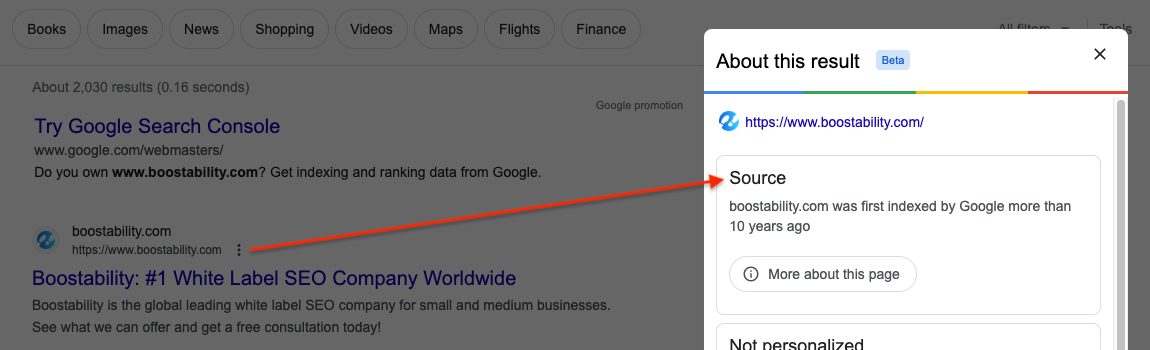
Method #2: Check with Google Search Console
The second tested method your business should check is through Google Search Console tool. Search Console provides a lot of data and information that is used in various ways. It can quickly check whether a page has been crawled and indexed, along with several other useful tools. In addition, you can use Google Search Console to prompt Google to crawl and index specific pages.

Follow these steps to get started:
- Set up a Google Search Console account.
- Once your property is verified, navigate to the search bar at the top of page.
- Input the full URL that you would like to check.
- Search Console will inform you whether the page has been crawled or indexed.
- Select “Request Indexing”.
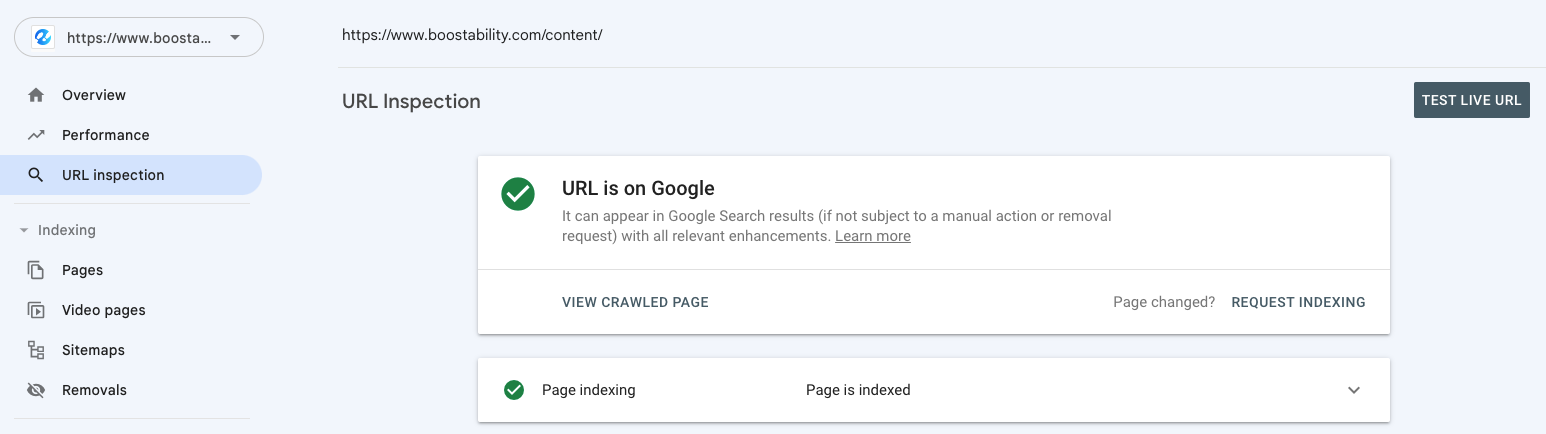
If the page hasn’t been crawled or indexed, you can easily submit a request by selecting “Request Indexing.” You can still request indexing anytime if the page is indexed but recently updated.